ChatGPT 8th place in ranking of 27 AI models: discover who surpassed it


Classifying artificial intelligence (AI) models can be complicated, but it often reveals insightful information about their capabilities and performance. Recently, a user experience-driven ranking placed ChatGPT in an unexpected 8th position among 27 analyzed AI models. This article explores the details of the ranking and who achieved higher placements.
Analysis of AI Models
The AI landscape can resemble the "wild west" in terms of innovation and competition, but there are initiatives aimed at establishing objective performance metrics. These initiatives are driven not only by the companies themselves but also by independent organizations seeking to provide a clear view of the capabilities of various AI tools.
Various abilities are evaluated, ranging from a chatbot's ability to perform mathematical calculations, generate images, demonstrate reasoning, offer medical advice, to its emotional intelligence. In these trials, the models show variations in performance, highlighting their strengths and weaknesses. For instance, while the GPT-5 model excels in scientific reasoning, it has been surpassed by models like Gemini and Claude in their ability to adapt to new concepts.
However, one of the metrics that is often missing in these evaluations is simply, which AI models provide the best user experience?
The Humaine Ranking System
A UK technology company called Prolific has developed a leaderboard called Humaine. Unlike other evaluations that focus on AI's ability to perform tasks, Prolific has prioritized users' experiences with different models.
By evaluating the experiences of 21,352 individuals who engaged in 21,352 interactions with the tools, a general winner was determined, and the results were broken down by age, location (with testing conducted in the UK and the US), and political beliefs.
Individual lists were created covering:
- UK: age groups
- UK: ethnicity
- UK: political opinion
- US: age groups
- US: ethnicity
- US: political opinion
Participants interacted with two AI models in a comparative manner, providing feedback on which performed better in each interaction. This not only resulted in an overall winner and a position on the performance table, but also separate rankings for performance in core tasks and reasoning, as well as recognition for communication, fluency, confidence, and ethics.
Ranking Results
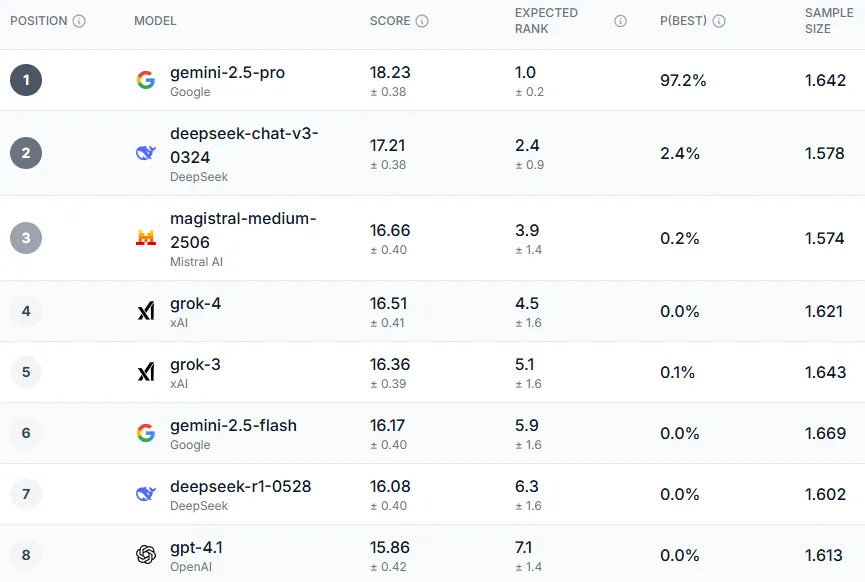
Following the survey, a clear winner emerged, not only in the overall performance category but in most of the subcategories. The Gemini 2.5-Pro model affirmed its top position in almost all evaluations offered by the test. Opinions were consistent across different demographic groups, including young individuals aged 18 to 34 in the UK, Democratic voters, and individuals over 55 in the US, all agreeing that Gemini 2.5 Pro was the best model overall. However, the only area where one model stood out above Gemini was in matters of trust, ethics, and safety, where Grok-3 received recognition, which is ironic given the recent controversy surrounding its ethics and safety issues.
The models that followed Gemini in the ranking were Deepseek, Magistral Le Chat, and Grok. Deepseek enjoyed great popularity earlier this year, although its presence has diminished. On the other hand, Le Chat, while less known, has a loyal user base.
ChatGPT's Position
In this competition, ChatGPT finds itself in a remarkably low position, ranking 8th, with the GPT-4.1 model achieving the best performance from OpenAI. Claude, on the other hand, performed even worse, placing its version 4 models in 11th and 12th place in the overall ranking.
Reflections on the Results
What does this mean for the perception of AI chatbots? Does it represent that Gemini is the best AI chatbot in the world? Does it mean that ChatGPT should be dismissed from the available options? The answer is not so simple.
The results do not necessarily reflect the superior performance of these models across other metrics. In tests involving various capabilities, models that commonly appear at the top include ChatGPT, Gemini, Claude, and Grok. This ranking offers a different perspective, providing valuable insights into the human experience associated with each model.
For example, Le Chat may not receive the highest scores in technical assessments, but it stands out as a highly regarded option in terms of experience and trust.
While Anthropic and OpenAI do not stand out in this specific round of tests, Gemini and Grok continue to offer solid performance. Both companies, known for their performance on benchmarks, maintain their competitive position in this new evaluation framework.
Exploring AI rankings based on user experiences provides a different angle that deserves consideration. This underscores the complexity of the competitive AI landscape, where technical performance and human interaction play crucial roles.
For more information on this and other topics related to artificial intelligence, I invite you to explore more content on my blog.