What is Web Scraping and Why is it Important? A Beginner's Guide

Web scraping is a technique used to extract data from websites. As online content continues to grow, web scraping has become a crucial tool for businesses, researchers, and developers. In this guide, we will delve into what web scraping is, how it works, and its importance in today's digital world.
What is Web Scraping?
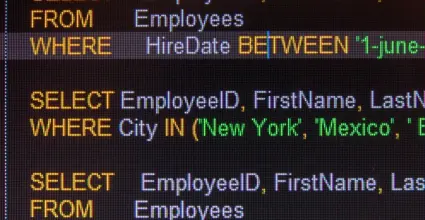
Web scraping involves gathering publicly available data from the web for analysis or later use. This process can include accessing and extracting information from price estimates, news articles, academic research data, among others. It is often performed using various programming languages and software tools.
Common Tools for Web Scraping
- Beautiful Soup: A Python library that makes it easy to extract data from HTML and XML files.
- Scrapy: A Python framework for building spiders that automates the scraping process.
- Selenium: A tool that allows users to control a web browser, useful for interacting with sites that require JavaScript.
- Octoparse: A visual scraper that doesn’t require programming, ideal for beginners.
- ParseHub: A visual tool that enables data extraction from complex websites.
How Does Web Scraping Work?
The web scraping process includes several fundamental steps:
1. Sending an HTTP Request
The scraper sends an HTTP request to the web page that contains the desired data. This can be done using libraries like requests in Python.
Read also


2. Receiving the Response
The web server processes the request and returns the page content, usually in HTML format.
3. Analyzing the Content
The returned HTML content is analyzed to identify and extract specific information. This is where libraries like Beautiful Soup or Scrapy come into play.
4. Data Storage
Finally, the extracted data is stored in an appropriate format, such as CSV, JSON, or SQL databases for later use.
Read also


Importance of Web Scraping
Web scraping is fundamental for several reasons, both for businesses and individuals.
Access to Updated Information
One of the biggest benefits of web scraping is the ability to access constantly updated information. This is vital for industries that rely on recent data, such as e-commerce and market research.
Competitor Analysis
Businesses can use web scraping to analyze pricing and offers from competitors. This information enables them to adjust their strategies and remain competitive in the market.
Research and Development
Academics and researchers can employ web scraping to gather large volumes of data from various sources, facilitating analysis and new research.
Automation of Tasks
Scraping allows for the automation of repetitive tasks, such as data collection, which saves time and human resources.
Ethical and Legal Considerations
While web scraping has many advantages, it is essential to consider ethical and legal aspects:
Terms of Service
Many websites have terms of service that specifically prohibit web scraping. It is crucial to review them and ensure compliance to avoid legal issues.
Robots.txt
The robots.txt files of websites indicate which parts of the site are allowed or disallowed for scraping. It is always advisable to check this file before starting the scraping process.
Server Load
Excessive scraping can cause unnecessary load on a server, so it is advisable to scrape responsibly and respect the site's usage policies.
Conclusion
Web scraping is a powerful tool that transforms the way individuals and businesses obtain and utilize data. While it offers numerous advantages, it also comes with responsibilities, and it is crucial to act ethically and legally. With a good understanding of what web scraping is and its implications, beginners can leverage this technique to benefit in their respective fields.
Additional Resources
As we move towards an increasingly digital world, web scraping will continue to play a vital role in data collection and analysis, becoming an essential skill in any technology professional's arsenal.