¿Qué es el Web Scraping y por qué es importante? Guía para principiantes

El web scraping es una técnica utilizada para extraer datos de sitios web. A medida que el contenido en línea sigue creciendo, el web scraping se ha convertido en una herramienta crucial para empresas, investigadores y desarrolladores. En esta guía, exploraremos en profundidad qué es el web scraping, cómo funciona y su importancia en el mundo digital actual.
¿Qué es el Web Scraping?
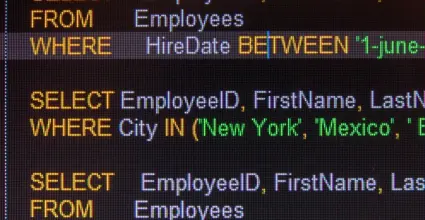
El web scraping involucra la recopilación de datos disponibles en la web para su análisis o uso posterior. Este proceso puede incluir el acceso y la extracción de información de estimaciones de precios, artículos de noticias, datos de investigaciones académicas, entre otros. A menudo, se realiza utilizando varios lenguajes de programación y herramientas de software.
Herramientas Comunes para Web Scraping
- Beautiful Soup: Una biblioteca de Python que facilita la extracción de datos de archivos HTML y XML.
- Scrapy: Un framework de Python para la creación de spiders, que automatiza el proceso de scraping.
- Selenium: Una herramienta que permite controlar un navegador web, útil para interactuar con sitios que requieren JavaScript.
- Octoparse: Un scraper visual que no requiere programación, ideal para principiantes.
- ParseHub: Herramienta visual que permite extraer datos de sitios web complejos.
¿Cómo Funciona el Web Scraping?
El proceso de web scraping incluye varios pasos fundamentales:
1. Envío de una Solicitud HTTP
El scraper envía una solicitud HTTP a la página web que contiene los datos deseados. Esto puede hacerse utilizando bibliotecas como requests en Python.
Lee también


2. Recepción de la Respuesta
El servidor web procesa la solicitud y devuelve el contenido de la página, normalmente en formato HTML.
3. Análisis del Contenido
El contenido HTML devuelto es analizado para identificar y extraer información específica. Esto es donde entran en juego las bibliotecas como Beautiful Soup o Scrapy.
4. Almacenamiento de Datos
Finalmente, los datos extraídos se almacenan en un formato adecuado, como CSV, JSON o bases de datos SQL para su posterior uso.
Lee también


Importancia del Web Scraping
El web scraping es fundamental por varias razones, tanto para empresas como para individuos.
Acceso a Información Actualizada
Uno de los mayores beneficios del web scraping es la capacidad de acceder a información actualizada constantemente. Esto es vital para industrias que dependen de datos recientes, como el comercio electrónico y la investigación de mercado.
Análisis de la Competencia
Las empresas pueden usar el web scraping para analizar precios y ofertas de la competencia. Esta información les permite ajustar sus estrategias y mantenerse competitivos en el mercado.
Investigación y Desarrollo
Los académicos y investigadores pueden emplear el web scraping para recopilar grandes volúmenes de datos de diversas fuentes, facilitando análisis y nuevas investigaciones.
Automatización de Tareas
El scraping permite la automatización de tareas repetitivas, como la recolección de datos, lo que ahorra tiempo y recursos humanos.
Consideraciones Éticas y Legales
Aunque el web scraping tiene muchas ventajas, es fundamental haber en cuenta consideraciones éticas y legales:
Términos de Servicio
Muchos sitios web tienen términos de servicio que prohíben específicamente el web scraping. Es esencial revisarlos y asegurarse de que se está cumpliendo con ellos para evitar problemas legales.
Robots.txt
Los archivos robots.txt de los sitios web indican que se permite o prohíbe el scraping de ciertas partes del sitio. Siempre es recomendable revisar este archivo antes de iniciar el scraping.
Carga en el Servidor
El scraping excesivo puede provocar una carga innecesaria en un servidor, por lo que es recomendable hacer scraping de manera responsable y respetar las políticas de uso del sitio.
Conclusión
El web scraping es una herramienta poderosa que transforma la forma en que los individuos y empresas obtienen y utilizan datos. Si bien ofrece numerosas ventajas, también viene con responsabilidades, y es crucial actuar ética y legalmente. Con un buen entendimiento de qué es el web scraping y sus implicaciones, los principiantes pueden aprovechar esta técnica para beneficiarse en sus respectivas áreas.
Recursos Adicionales
A medida que avanzamos hacia un mundo más digitalizado, el web scraping seguirá desempeñando un papel vital en la recopilación y análisis de datos, convirtiéndose en una habilidad esencial en el arsenal de cualquier profesional del ámbito tecnológico.